

Ben je benieuwd naar de implementatie van deze code? Je kunt de repository vinden op github
De uitdaging: perfecte golven voor elke surfer
Als ervaren surfer weet je dat de perfecte golf voor een professional, voor een beginner chaos kan betekenen. Hoewel er veel voorspellingssites en zelfs WhatsApp-diensten bestaan die golfcondities delen, missen deze vaak het persoonlijke element zoals je surfniveau. Wat als je precies zou kunnen vastleggen onder welke condities jij het beste surft? Met deze vraag in gedachten ontstond het idee om een intelligente golfconditie-applicatie te ontwikkelen.
Het doel was helder: een systeem ontwikkelen dat surfers in staat stelt hun ideale surfcondities te registreren en te analyseren. De applicatie moet niet alleen actuele golfcondities tonen, maar deze ook classificeren per ervaringsniveau, rekening houdend met cruciale parameters zoals golfhoogte, golffrequentie, windsterkte en windrichting.
Architectuur: de fundamenten leggen
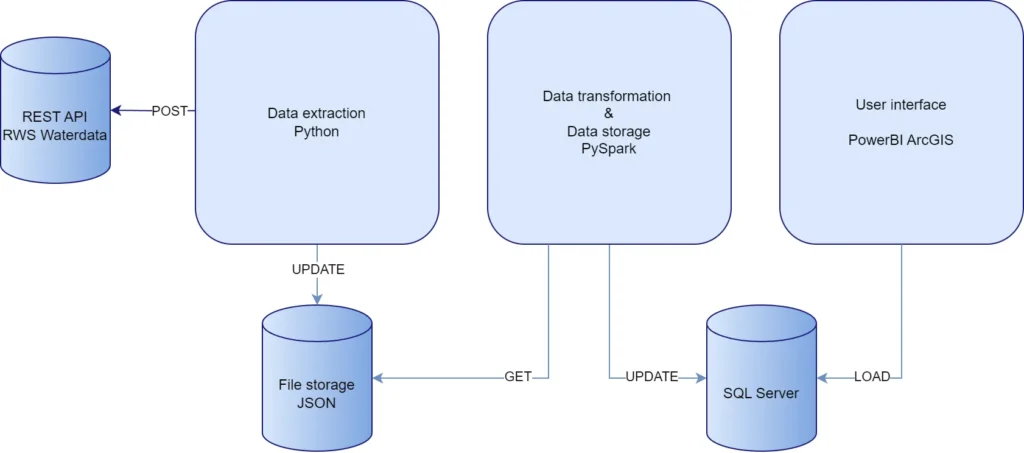
Voor de eerste fase van de applicatieontwikkeling is gekozen voor een robuuste lokale ontwikkelomgeving met drie kerncomponenten:
- Data-extractie: een Python-gebaseerd systeem voor het ophalen van data via Rijkswaterstaat-API’s
- Data-transformatie: PySpark voor efficiënte dataverwerking en -analyse
- Data-opslag: Microsoft SQL Server voor gestructureerde dataopslag
Deze architectuur vormt de basis voor wat later zal worden gemigreerd naar de Cloud.
Technologiekeuzes: bouwen voor de toekomst
De technologiekeuzes zijn gebaseerd op drie kernprincipes: schaalbaarheid, betrouwbaarheid en toekomstbestendigheid.
Python voor data-extractie
De keuze voor Python was vanzelfsprekend vanwege de uitstekende ondersteuning voor API-integraties. Het uitgebreide Python-ecosysteem biedt alle tools die nodig zijn voor dataverwerking en -analyse, met name voor het ophalen van data van Rijkswaterstaat.
Apache Spark voor dataverwerking
Apache Spark, specifiek PySpark, werd geselecteerd vanwege drie cruciale voordelen:
- Efficiënte verwerking van grote datasets door capaciteitsverdeling
- Naadloze integratie met Python
- Ingebouwde functionaliteit voor data-analyse en machine learning
Microsoft SQL Server voor dataopslag
Voor de databaselaag is Microsoft SQL Server gekozen, met het oog op:
- Robuuste opslag van gestructureerde data
- Optimale ondersteuning voor het star schema datamodel
- Naadloze toekomstige migratie naar Microsoft Fabric
Technische architectuur in detail
De architectuur is opgezet volgens het principe van gescheiden verantwoordelijkheden, waarbij elke component een specifieke taak heeft:

Deze opzet maakt het mogelijk om:
- Onafhankelijk te schalen per component
- Eenvoudig nieuwe databronnen toe te voegen
- Flexibel te zijn in de keuze van visualisatietools
Van concept naar werkende applicatie
De implementatie volgde een gestructureerde aanpak, waarbij eerst de basis werd gelegd met een werkende datapipeline. Een van de eerste uitdagingen was het correct opzetten van de ontwikkelomgeving, vooral wat betreft de versiecompatibiliteit tussen verschillende componenten.
Een lokale ontwikkelomgeving is van belang om zo snel mogelijk het concept te testen. Het biedt flexibiliteit in het beheren van omgevingsvariabelen. Door snel te kunnen falen zonder direct een dure Cloud omgeving op te zetten, kan het concept tegen lage kosten worden getest.
Technische implementatie
Ontwikkelomgeving opzetten
Voor een werkende ontwikkelomgeving zijn de volgende componenten nodig:
# Vereiste versies
- Java 17.0.12
- Hadoop 3.4.0
- Spark 3.5.4
- Python 3.8
- PySpark 3.5.4
Het is cruciaal dat deze versies compatibel zijn. De installatie verloopt als volgt:
- Java installatie:
- Download JDK 17.0.12
- Configureer JAVA_HOME environment variable
- Voeg de locatie van Java aan het system PATH toe: %JAVA_HOME%\bin
- Hadoop configuratie:
# Environment variables
- HADOOP_HOME=C:\hadoop-3.4.0
- PATH=%HADOOP_HOME%\bin
- Winutils.exe moet aanwezig zijn in de Hadoop bin directory
- Spark setup:
# Environment variables
- SPARK_HOME=C:\spark-3.5.4
- PATH=%SPARK_HOME%\bin
Data-extractie implementatie
De data-extractie van Rijkswaterstaat gebeurt via hun REST API. Het ophalen van data uit de API werkt met een post request met een JSON body. In de body wordt gespecificeerd wat er precies opgehaald dient te worden. Zo kun je aangeven wat de locatie, parameters en tijdsinterval van de metingen zijn. De request wordt opgeslagen in een JSON file.
import requests
import json
import pandas as pd
collect_observations = ('https://waterwebservices.rijkswaterstaat.nl/' +
'ONLINEWAARNEMINGENSERVICES_DBO/' +
'OphalenWaarnemingen')
# Voorbeeld request
request = {'Locatie': {'X': 514618.822878979, 'Y': 5896433.91304204, 'Naam': 'K13 Alpha', 'Code': 'K13'}, 'AquoPlusWaarnemingMetadata': {'AquoMetadata': {'Compartiment': {'Code': 'LT'}, 'Grootheid': {'Code': 'WINDRTG'}}}, 'Periode': {'Begindatumtijd': '2024-10-01T14:00:00.000+01:00', 'Einddatumtijd': '2024-10-01T16:00:00.000+01:00'}}
resp = requests.post(collect_observations, json=request)
resp = resp.json()
output_file = './../Data/Raw/test.json'
with open(output_file, 'w') as f:
json.dump(resp, f, indent=4)
PySpark data transformatie
Voor de data transformatie is een robuuste PySpark pipeline opgezet. Eerst wordt een PySpark sessie opgestart. PySpark kan een JSON in een dataframe laden aan de hand van een schema. Deze JSON heeft meerdere lijnen dus wordt deze parameter meegegeven aan de JSON functie. Vervolgens worden de dataframe omgezet naar meerdere rijden. De kolom namen worden herschreven en herstructureerd.[SZ1]
from pyspark.sql import SparkSession
from pyspark import SparkConf
from pyspark.sql.types import StructType, StructField, StringType, DoubleType, ArrayType, LongType
from pyspark.sql.functions import explode, col
import os
jars_dir = "C:\sqljdbc_12.8\enu\jars"
jdbc_driver_path = [os.path.join(jars_dir, i) for i in os.listdir(jars_dir)]
jdbc_driver_path = ",".join(jdbc_driver_path)
# Update Spark configuration
conf = SparkConf().setMaster("local[*]") \
.set("spark.sql.debug.maxToStringFields", 1000) \
.set("spark.executor.heartbeatInterval", "200000") \
.set("spark.network.timeout", "300000") \
.set("spark.sql.execution.arrow.pyspark.enabled", "true") \
.set("spark.jars", jdbc_driver_path) \
.set("spark.ui.port", "4040") \
.set("spark.driver.cores", "8") \
.set("spark.executor.cores", "8") \
.set("spark.driver.memory", "16g") \
.set("spark.executor.memory", "16g") \
.set("spark.executor.instances", "2") \
.setAppName("PYSPARK_MSSQL_TUTORIAL")
spark = SparkSession.builder.config(conf=conf).getOrCreate()
sc = spark.sparkContext
sc.setLogLevel("WARN")
# Define the schema
schema = StructType([
StructField("WaarnemingenLijst", ArrayType(StructType([
StructField("Locatie", StructType([
StructField("Locatie_MessageID", LongType(), True),
StructField("Coordinatenstelsel", StringType(), True),
StructField("X", DoubleType(), True),
StructField("Y", DoubleType(), True),
StructField("Naam", StringType(), True),
StructField("Code", StringType(), True)
]), True),
StructField("MetingenLijst", ArrayType(StructType([
StructField("Tijdstip", StringType(), True),
StructField("Meetwaarde", StructType([
StructField("Waarde_Numeriek", DoubleType(), True)
]), True)
]), True), True),
StructField("AquoMetadata", StructType([
StructField("Parameter_Wat_Omschrijving", StringType(), True),
StructField("Compartiment", StructType([
StructField("Code", StringType(), True)
]), True),
StructField("Grootheid", StructType([
StructField("Code", StringType(), True)
]), True),
StructField("Eenheid", StructType([
StructField("Code", StringType(), True)
]), True)
]), True)
]), True), True)
])
# Read the JSON file into a DataFrame using the schema
df = spark.read.json( \
path="c:/Users/Admin/Documents/Programming projects/GolfconditiesApp/Data/Raw/RWS_J6_Hm0.json", \
schema=schema, \
multiLine=True \
)
# Select and explode the nested fields to get the desired columns
df_exploded = df.select(
explode("WaarnemingenLijst").alias("Waarnemingen")
).select(
col("Waarnemingen.Locatie.X").alias("X_coordinate"),
col("Waarnemingen.Locatie.Y").alias("Y_coordinate"),
col("Waarnemingen.Locatie.Naam").alias("Name"),
col("Waarnemingen.Locatie.Code").alias("Location_Code"),
col("Waarnemingen.AquoMetadata.Parameter_Wat_Omschrijving").alias("description"),
col("Waarnemingen.AquoMetadata.Compartiment.Code").alias("compartiment_code"),
col("Waarnemingen.AquoMetadata.Grootheid.Code").alias("parameter_code"),
col("Waarnemingen.AquoMetadata.Eenheid.Code").alias("unit_code"),
explode("Waarnemingen.MetingenLijst").alias("Metingen")
).select(
col("Location_Code"),
col("X_coordinate"),
col("Y_coordinate"),
col("Name"),
col("description"),
col("compartiment_code"),
col("parameter_code"),
col("unit_code"),
col("Metingen.Tijdstip").alias("date_time"),
col("Metingen.Meetwaarde.Waarde_Numeriek").alias("measurement_value")
)
# Show the resulting DataFrame
df_exploded.show()
Coördinatentransformatie
Een belangrijke technische uitdaging was de transformatie van coördinatenstelsels. Voor spatial data worden verschillende coördinatensystemen gebruikt. De ArcGIS map in PowerBI werkt standaard met het EPSG 4326 coördinatensysteem. Om alle locatie coördinaten om te schrijven wordt pyproj library gebruikt:
from pyproj import Transformer
from pyspark.sql.functions import udf
from pyspark.sql.types import DoubleType
# Create coordinate transformer
transformer = Transformer.from_crs("EPSG:25831", "EPSG:4326")
# Define UDFs to convert coordinates
def convert_x_to_lon(x, y):
return transformer.transform(x, y)[0]
def convert_y_to_lat(x, y):
return transformer.transform(x, y)[1]
convert_x_to_lon_udf = udf(lambda x, y: convert_x_to_lon(x, y), DoubleType())
convert_y_to_lat_udf = udf(lambda x, y: convert_y_to_lat(x, y), DoubleType())
# Create new columns for converted coordinates
df_converted = df_exploded.withColumn("Longitude", convert_x_to_lon_udf(df_exploded["X_coordinate"], df_exploded["Y_coordinate"])) \
.withColumn("Latitude", convert_y_to_lat_udf(df_exploded["X_coordinate"], df_exploded["Y_coordinate"]))
# Drop old columns
df_converted = df_converted.drop("X_coordinate", "Y_coordinate")
# Rename new columns to original names
df_converted = df_converted.withColumnRenamed("Longitude", "Y_coordinate") \
.withColumnRenamed("Latitude", "X_coordinate")
# Show the result
df_converted.show()
Database structuur
Het geïmplementeerde star schema bestaat uit:
- Een centrale fact-tabel voor locatiemetingen
- Dimensietabellen voor locaties en tijdstippen
- Gespecialiseerde tabellen voor verschillende meetwaarden
Het transformeren van de data naar een starschema gebeurt in meerdere stappen. Het startpunt is een dataframe met alle mogelijke kollommen en een rij per locatie en meting. De parameter van de meting, de locatie en de datum-tijd combinatie maakt een meting uniek. Echter bevat de feitentabel rijen op basis van een unieke datum-tijd en locatie combinatie, maar met alle vier de verschillende metingen op de zelfde datum-tijd en locatie.
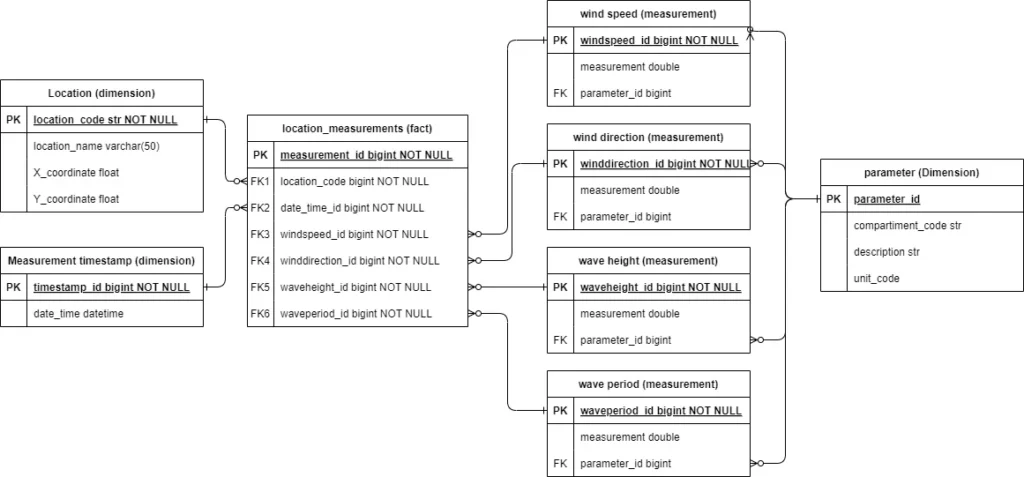
Dimensietabellen
Vanuit de start dataframe worden eerst de dimensie tabellen gefilterd. Elke unieke rij krijgt hier een uniek ID. Er zijn bijvoorbeeld meerdere metingen per datum-tijd, maar elke unieke datum-tijd krijg zijn eigen ID. Voor de locatie wordt de locatie code gebruikt.
from pyspark.sql.functions import col, monotonically_increasing_id
# Create dimension tables with unique IDs
timestamp_dim = df_final.select(
col("date_time")
).distinct().withColumn("timestamp_id", monotonically_increasing_id() + 1)
Meetwaarde tabellen
Voor de meetwaarde tabellen wordt een nieuwe tabel gemaakt op basis van de specifieke parameter code. Een selectie kolommen wordt mee gekopieerd. Voor iedere rij wordt een uniek ID toegekend. Vervolgens wordt de parameter dimensie tabel aan de meetwaarde tabel gevoegd op basis van een combinatie van kolommen. Daarna worden alleen de benodigde kolommen gefilterd om uit te komen op een zo minimaal mogelijke tabel.
windspeed_dim = df_final.filter(col("parameter_code") == "WINDSHD").select(
col("date_time"),
col("Location_Code").alias("location_code"),
col("parameter_code"),
col("compartiment_code"),
col("unit_code"),
col("description"),
col("measurement_value").alias("windspeed_measurement")
).distinct().withColumn("windspeed_id", monotonically_increasing_id() + 1
).join(
parameter_dim.select(
col("parameter_id"),
col("compartiment_code"),
col("unit_code"),
col("description")
),
on=["compartiment_code", "unit_code","description"],
how="left"
).select(
col("date_time"),
col("location_code"),
col("parameter_code"),
col("windspeed_id"),
col("parameter_id"),
col("windspeed_measurement")
)
Feitentabel
De feitentabel wordt eerst opgebouwd door alle tabellen met elkaar te combineren, en vervolgens alleen de benodigde kolommen te behouden. Vanuit de start dataframe wordt een nieuwe dataframe geselecteerd op basis van de unieke datum-tijd en locatiecode combinatie en een uniek ID toegekend. Dit is het uiteindelijke meet ID. Aan deze tabel worden vervolgens de meetwaarden per parameter toegevoegd op locatie en datum-tijd. Vervolgens worden de dimensietabellen en meettabellen ook toegevoegd. Dit is nodig om er voor te zorgen dat de foreign keys van alle tabellen op de juiste rijen terecht komen.
# Create fact table with distinct date_time and location_code
location_measurement_fact = df_final.select(
col("date_time"),
col("Location_Code").alias("location_code"),
).distinct().withColumn("measurement_id", monotonically_increasing_id() + 1)
# Add measurements for specific measurement types
location_measurement_fact = location_measurement_fact.join(
df_final.filter(col("parameter_code") == "WINDSHD").select(
col("date_time"),
col("Location_Code").alias("location_code"),
col("measurement_value").alias("windspeed_measurement")
),
on=["date_time", "location_code"],
how="left"
).join(
df_final.filter(col("parameter_code") == "WINDRTG").select(
col("date_time"),
col("Location_Code").alias("location_code"),
col("measurement_value").alias("winddirection_measurement")
),
on=["date_time", "location_code"],
how="left"
).join(
df_final.filter(col("parameter_code") == "Hm0").select(
col("date_time"),
col("Location_Code").alias("location_code"),
col("measurement_value").alias("waveheight_measurement")
),
on=["date_time", "location_code"],
how="left"
).join(
df_final.filter(col("parameter_code") == "Tm02").select(
col("date_time"),
col("Location_Code").alias("location_code"),
col("measurement_value").alias("waveperiod_measurement")
),
on=["date_time", "location_code"],
how="left"
).join(
location_dim,
on="location_code",
how="left"
).join(
timestamp_dim,
on="date_time",
how="left"
).join(
windspeed_dim,
on=["date_time", "location_code", "windspeed_measurement"],
how="left"
).join(
winddirection_dim,
on=["date_time", "location_code","winddirection_measurement"],
how="left"
).join(
waveheight_dim,
on=["date_time", "location_code","waveheight_measurement"],
how="left"
).join(
waveperiod_dim,
on=["date_time", "location_code", "waveperiod_measurement"],
how="left"
)
location_measurement_fact.show()
Als laatste stap worden alleen de benodigde kolommen gefilterd. De tabel bevat dan alleen nog de primary keys, en alle foreign keys.
Database connectie en data-opslag
De connectie tussen PySpark en SQL Server wordt opgezet met de JDBC driver. De locatie van de Mircosoft SQL Server is op localhost poort 14:33. Belangrijk is om de server zo in te stellen dat de database gebruiker toegang heeft tot de database. De gebruikersnaam en wachtwoord worden ingeladen uit een lokaal bestand. Een PySpark dataframe heeft methoden om direct een tabel naar een database te schrijven.
import configparser
# Define the connection properties
config = configparser.ConfigParser()
config.read('./../credentials')
db_ip = "localhost:1433"
db_name = "data_structure_v3"
db_username = config['database']['username']
db_password = config['database']['password']
driver = "com.microsoft.sqlserver.jdbc.SQLServerDriver"
jdbc_url = f"jdbc:sqlserver://{db_ip};databaseName={db_name};username={db_username};password={db_password};TrustServerCertificate=True;"
# Write the dimension tables to the database
def write_to_database(df, table_name):
df.write \
.format("jdbc") \
.option("url", jdbc_url) \
.option("dbtable", table_name) \
.option("driver", driver) \
.mode("overwrite") \
.save()
write_to_database(location_dim, "location_dim")
# Stop the SparkSession
spark.stop()
Data visualisatie
Voor de visualisatie in Power BI is een directe connectie met de SQL Server database opgezet. Het datamodel in Power BI reflecteert het star schema uit de database, wat resulteert in efficiënte queries en snelle visualisaties.
Eerste successen
De eerste end-to-end-test was een mijlpaal: de data van vier meetlocaties kon worden opgehaald, verwerkt en gevisualiseerd. Een interessante uitdaging die zich voordeed was de conversie van coördinatenstelsels – de data van Rijkswaterstaat gebruikte een ander systeem dan wat nodig was voor de visualisaties.
Resultaten en visualisaties
Prestaties
Het systeem verwerkt momenteel data van vier meetlocaties met de volgende karakteristieken:
- Update frequentie: elke 10 minuten
- Gemiddelde verwerkingstijd: <30 seconden
- Datavolume: ~1000 metingen per dag per locatie
- Query responstijd in Power BI: <2 seconden
Visualisaties
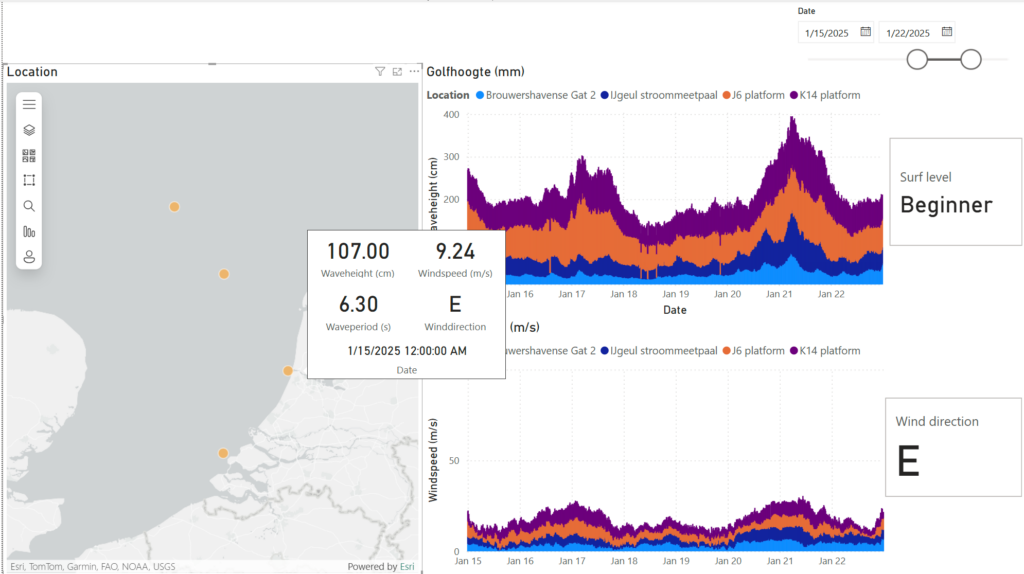
Het MVP toont nu een interactieve kaart met vier meetlocaties. Als gebruiker kun je:
- Golfhoogte en windsnelheid per locatie bekijken
- Surfniveau-indicaties zien (“flat”, “beginner”, “intermediate”, “advanced”, “choppy”)
- Windrichtingen bekijken
- Data filteren op specifieke tijdvakken
De visualisaties zijn interactief – het selecteren van een locatie of tijdstip update alle gekoppelde weergaven.
Technische uitdagingen en oplossingen
- Versiecompatibiliteit: Het vinden van de juiste versiecombinaties voor Java, Spark en Python was cruciaal. De uiteindelijke configuratie is getest op stabiliteit en performance.
- Dataconsistentie: Door het gebruik van een star schema en strikte foreign key constraints is de data-integriteit gewaarborgd.
- Coördinatentransformatie: De conversie van coördinatenstelsels is opgelost met pyproj, wat nauwkeurige locatieweergave mogelijk maakt.
- Performance optimalisatie: Door het gebruik van indexen en partitionering is de query performance geoptimaliseerd:
Learnings en volgende stappen
Belangrijke inzichten uit deze eerste fase:
- Het belang van een goed doordacht datamodel
- De waarde van een toekomstbestendige architectuur die klaar is voor cloudmigratie
- Het belang van gestandaardiseerde datatransformaties, vooral bij het werken met verschillende coördinatenstelsels
Vooruitblik
Met de lokale ontwikkelomgeving nu volledig operationeel, ligt de focus op de volgende uitdaging: de migratie naar Microsoft Fabric in de cloud. In het volgende deel van deze serie wordt dieper ingegaan op deze transitie en de uitdagingen die daarbij komen kijken.
Dit is het eerste deel in een serie over de ontwikkeling van een intelligente golfconditie-applicatie. In het volgende deel staat de migratie naar de cloud centraal.