

Dit is het vijfde en laatste deel van onze blogreeks over het bouwen van een surfconditie-analyseplatform. In de vorige artikelen heb ik de opzet van onze lokale omgeving, de migratie naar de cloud, de visualisatie op web en een alternatief dataplatform besproken. In dit laatste deel focus ik op het toevoegen van machine learning voor intelligente surfniveau-voorspellingen.
De uitdaging: intelligentie toevoegen aan golfdata
Het hoofddoel van mijn machine learning implementatie is om surfers te helpen bij het bepalen of de condities geschikt zijn voor hun niveau. Elke surfer, van beginner tot gevorderd, heeft specifieke golfcondities nodig om veilig en plezierig te kunnen surfen.
De concrete uitdaging was om automatisch een surfniveau (beginner, intermediate, advanced, etc.) te voorspellen op basis van vier kritieke parameters:
- Golfhoogte (in cm)
- Golfperiode (in seconden)
- Windrichting (in graden)
- Windsnelheid (in m/s)
Deze proof-of-concept is bedoeld als basis voor verdere ontwikkeling, waarbij gebruikersfeedback en meerdere locaties kunnen worden toegevoegd.
Architectuur: integratie van ML in het dataplatform
Om machine learning succesvol te integreren in ons bestaande dataplatform, heb ik enkele nieuwe componenten toegevoegd aan onze architectuur. Het ML-model wordt op twee momenten in het proces gebruikt:
- Training fase: los van de reguliere datapipeline wordt het model getraind met historische golfdata
- Transformatie fase: in de datapipeline wordt het getrainde model gebruikt om nieuw binnenkomende data automatisch te classificeren
Het machine learning model wordt specifiek ingezet tijdens de data-transformatiestap. Nadat de ruwe data is ingeladen, worden de surfcondities automatisch gecategoriseerd op niveau voordat ze worden opgeslagen en gevisualiseerd.
Data-voorbereiding: de sleutel tot succes
Voor een effectief machine learning model was zorgvuldige datavoorbereiding essentieel. Dit proces bestond uit drie hoofdstappen:
1. Labelen van de data
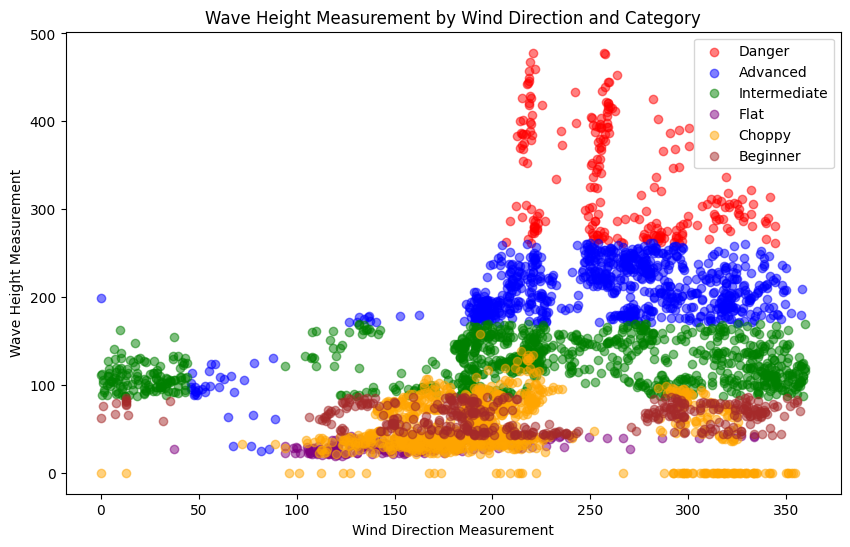
Eerst heb ik onze dataset van de IJgeul stroommeetpaal (met 3805 meetmomenten) gelabeld op basis van een algoritme met 14 verschillende regels. Om te voorkomen dat het model te eenvoudig lineaire patronen zou herkennen, heb ik kleine willekeurige afwijkingen toegevoegd aan de grenswaarden:
dataset_classified = dataset_0.withColumn(
"category",
when(col("waveperiod_measurement") < 4, "Choppy")
# Onshore winds
.when((col("winddirection_measurement") >= 90 + random.uniform(-20,20)) &
(col("winddirection_measurement") <= 140) &
(col("windspeed_measurement") > 90), "Danger")
.when((col("waveheight_measurement") <= 150 + random.uniform(-20,20)) &
(col("windspeed_measurement") <= 20) &
(col("winddirection_measurement") <= 90) &
(col("winddirection_measurement") >= 45) &
(col("winddirection_measurement") <= 180), "Advanced")
# Meer regels volgen...
)
De resulterende dataset bevat zes categorieën: Beginner, Intermediate, Advanced, Choppy, Flat en Danger.
2. Splitsen van de dataset
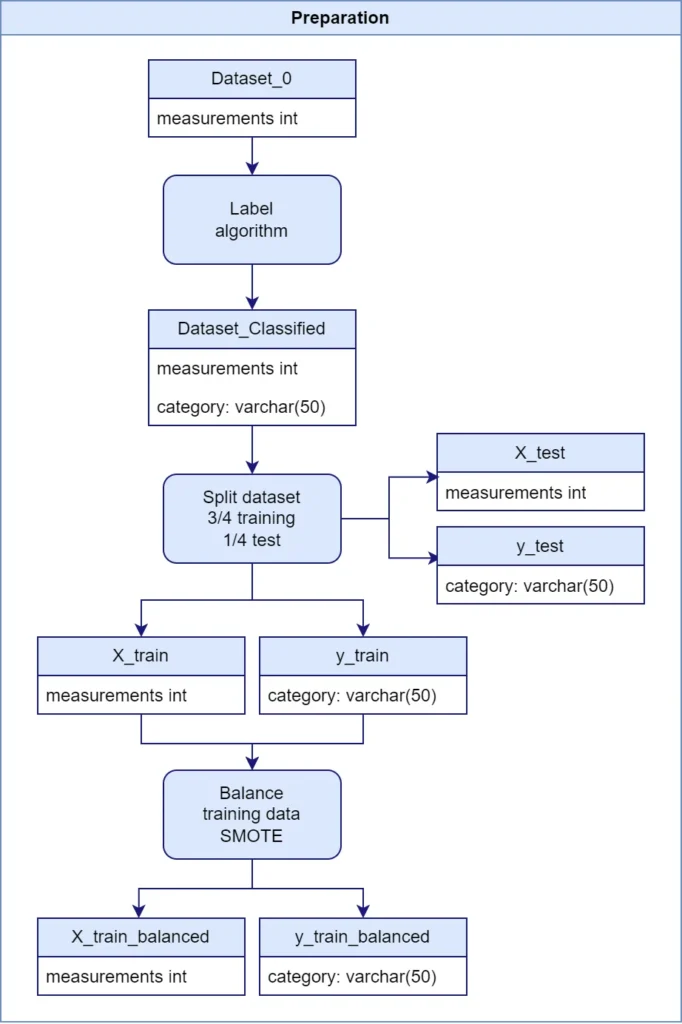
Vervolgens heb ik de dataset gesplitst in trainings- en testgegevens:
- 75% (2853 rijen) voor training
- 25% (952 rijen) voor testen
Deze splitsing stelt mij in staat om het model te trainen op het grootste deel van de data en de effectiviteit te valideren op een afzonderlijke testset.
3. Balanceren van de data
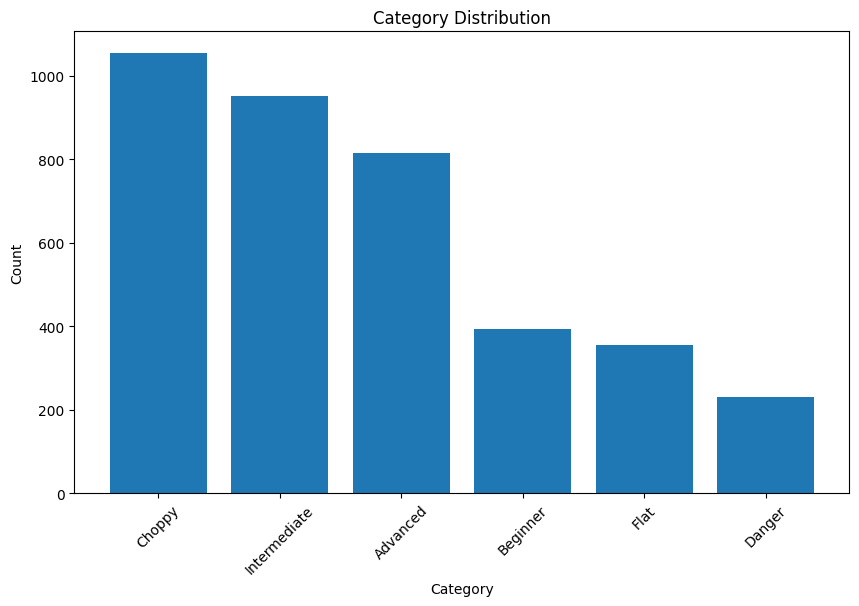
Om te zorgen dat het model eerlijk leert zonder bias naar oververtegenwoordigde categorieën, heb ik de SMOTE (Synthetic Minority Over-sampling Technique) methode toegepast om de trainingsdataset te balanceren:
from imblearn.over_sampling import SMOTE
smote = SMOTE(random_state=15)
X_train_balanced, y_train_balanced = smote.fit_resample(X_train, y_train)
Modelontwikkeling: support vector classification
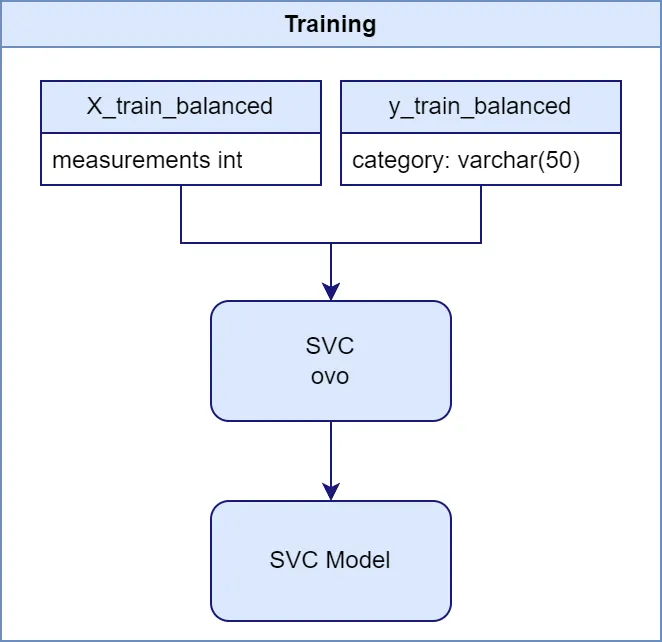
Na zorgvuldige afweging heb ik gekozen voor een Support Vector Machine (SVM) classifier met een one-vs-one (OvO) strategie. Deze keuze was gebaseerd op meerdere factoren:
- Type probleem: we hebben te maken met een multi-class classificatieprobleem (niet een regressieprobleem)
- Schaalbaarheid: het model wordt eenmalig getraind en kan daarna efficiënt worden toegepast op nieuwe data
- Dimensionaliteit: SVM kan goed omgaan met hoge-dimensionale data, wat belangrijk is als we later meer meetlocaties toevoegen
- Implementatiegemak: SVC met lineaire kernel is relatief eenvoudig te implementeren en te integreren in de datapipeline
Het trainingsproces was relatief eenvoudig met scikit-learn:
from sklearn.svm import SVC
# Create the SVC model
svc_model = SVC(kernel='linear', decision_function_shape='ovo', class_weight='balanced')
# Fit the model
svc_model.fit(X_train, y_train)
Validatie en resultaten
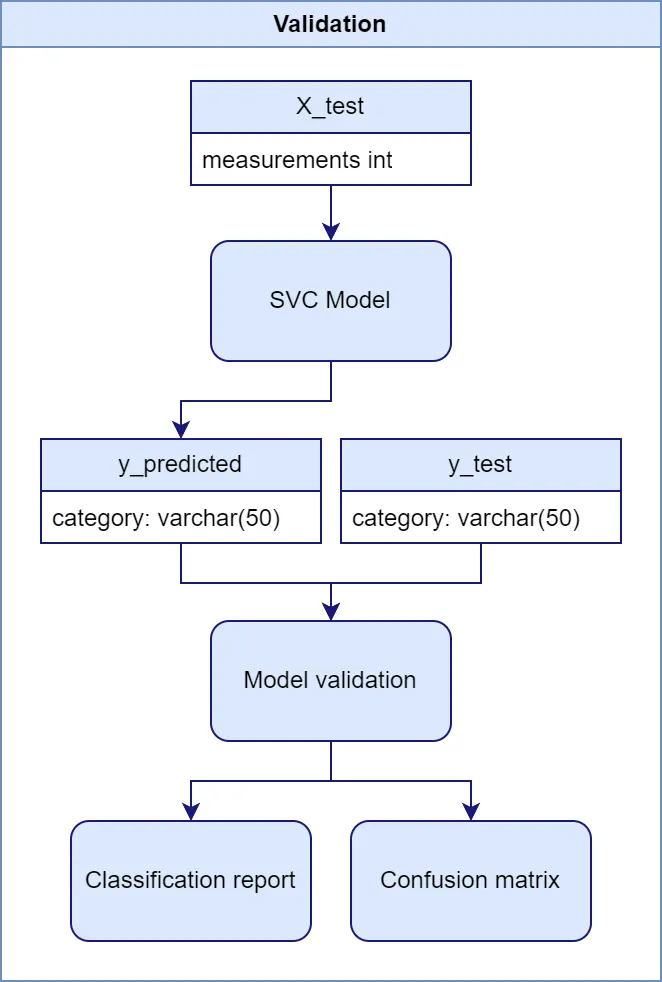
De prestaties van mijn model heb ik gevalideerd met behulp van een classificatierapport en een confusion matrix:
from sklearn.metrics import classification_report, confusion_matrix
# Predict the categories
y_pred = svc_model.predict(X_test)
# Print the classification report
print(classification_report(y_test, y_pred))
# Print the confusion matrix
print(confusion_matrix(y_test, y_pred))
De resultaten waren indrukwekkend:
- Overall accuracy: 98%
- F1-scores per categorie tussen 0.97 en 1.00
- Minimale verwarring tussen categorieën, voornamelijk tussen Advanced en Intermediate
De confusion matrix toonde aan dat er enkele vals-positieven waren, met name bij het voorspellen van de “Intermediate” categorie, maar over het algemeen was de prestatie uitstekend.
Ik heb ook de efficiëntie van het model gemeten:
- Trainingstijd: slechts 2,09 seconden
- Voorspellingstijd: 0,007 seconden per voorspelling
- Geheugengebruik: 1,41 MiB
Deze prestatiemetrieken bevestigen dat het model lichtgewicht en efficiënt genoeg is voor real-time toepassing in onze datapipeline.
Uitdagingen en oplossingen
De grootste uitdaging bij dit project was het bepalen van de juiste classificatiemethode en het voorbereiden van de data. Enkele specifieke uitdagingen en mijn oplossingen waren:
- Data labeling: in een ideale situatie zou een surfexpert handmatig de condities classificeren. Voor deze proof-of-concept heb ik een algoritme met logische regels en willekeurige variatie gebruikt.
- Modelkeuze: het selecteren van het juiste model vereiste zorgvuldige afweging van verschillende factoren zoals datavolume, complexiteit en verwerkingssnelheid.
- Databalans: de ongebalanceerde verdeling van categorieën in de oorspronkelijke dataset kon leiden tot een biased model. SMOTE hielp dit probleem op te lossen.
Toekomstige uitbreidingen
Dit machine learning model vormt de basis voor verdere intelligente functionaliteiten:
- Meer meetlocaties en parameters: het huidige model gebruikt slechts vier parameters van één locatie. Door meer locaties en parameters toe te voegen, kunnen we de nauwkeurigheid verder verbeteren.
- Gebruikersfeedback integreren: we kunnen het model personaliseren door gebruikers te laten aangeven of de voorspellingen kloppen met hun ervaring op een bepaalde surfspot.
- Proactieve notificaties: een ideale uitbreiding zou surfers automatisch waarschuwen wanneer perfecte condities voor hun niveau worden voorspeld.
- Locatie-specifieke modellen: elke surflocatie heeft unieke kenmerken. In de toekomst kunnen we specifieke modellen per surfspot ontwikkelen.
Meer surfplezier en betere beslissingen door machine learning
Met de toevoeging van machine learning heb ik ons surfplatform naar een hoger niveau getild. Door geavanceerde algoritmen te combineren met onze eerder ontwikkelde data-infrastructuur, kunnen we nu intelligente aanbevelingen doen die afgestemd zijn op het niveau van individuele surfers.
Deze intelligente laag maakt het platform niet alleen krachtiger, maar ook persoonlijker voor elke gebruiker. Het stelt surfers in staat om beter geïnformeerde beslissingen te nemen over wanneer en waar ze gaan surfen, wat zowel de veiligheid als het plezier bevordert.
Dit artikel sluit mijn vijfdelige blogreeks af over het bouwen van een intelligent surfconditie-analyseplatform. Alle artikelen uit deze serie worden binnenkort gebundeld in een uitgebreide whitepaper met extra technische details en implementatierichtlijnen. Wil je toch alvast de blogs lezen, lees dan blog 1 over de lokale setup, blog 2 over de migratie naar de cloud, blog 3 over de webinterface en blog 4 over de analyse van FME als mogelijk alternatief voor het ETL-proces in de golfconditie-applicatie.